快学Scala-13-集合
主要的集合特质
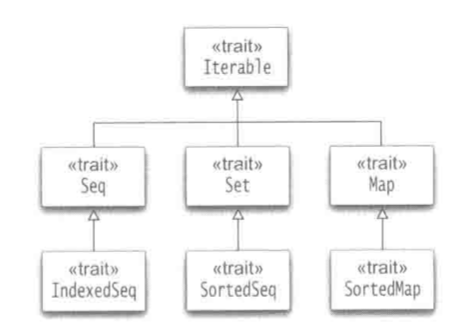
上图表示了Scala中集合类继承关系中的关键特质
Iterable指能够提供一个遍历集合中每个元素的方法
seq是有先后次序的值的序列,比如数组和列表
IndexedSeq允许我们通过整型下标快速访问任意元素
Set是没有先后顺序的集合
SortedSet中元素以某种顺序被访问
Map是一组一组元素的集合
SortedMap是按照键的某种顺序访问其中的实体
每个Scala集合特质或类都有一个带有apply方法的伴生对象,这个apply方法可以用来构建该集合中的实例
1 | |
这样的设计叫做统一创建原则
不同集合间可以相互转换,常见方法有toSeq,toSet,toMap等,还有范型方法to[C]
1 | |
同类集合间进行比较可以用===,是值的比较,不通类型集合间比较,需要用sameElements方法
可变和不可变集合
Scala支持可变和不可变两种集合,不可变集合从不改变,可以安全的共享引用,多线程中也没有问题。
scala.collection.mutable.map 和 scala.collection.immutable.map 有共同的超类scala.collection.map。分别对应可变和不可变的map
Scala优先采用不可变集合,
1 | |
不可变集类似于Java中的String,每次对其修改都是产生了一个新的集,不同点在于,如果新集中加入了老集已有的元素,则这个元素是引用。
序列
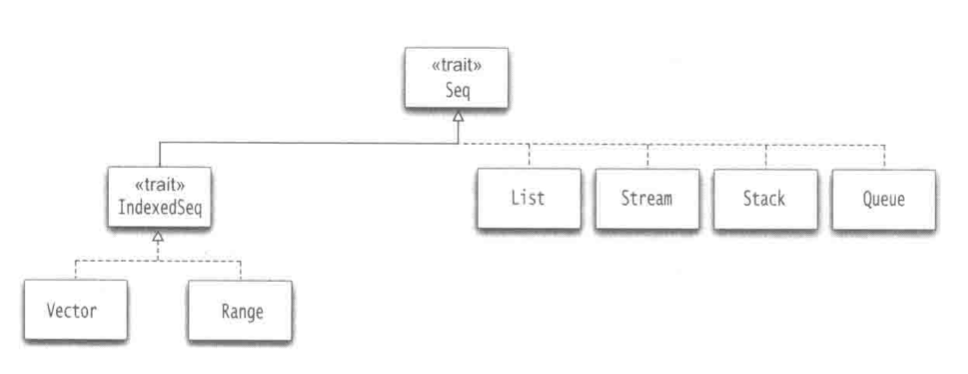
上图展示了Scala中的不可变序列
Vector是ArrayBuffer的不可变版本,支持快速随机访问。向量是以树形结构(类似b+树)的形式实现的。
Range表示一个整数序列,range对象不存储所有值,只存储开始,结束和增值。用to和until方法来构造。
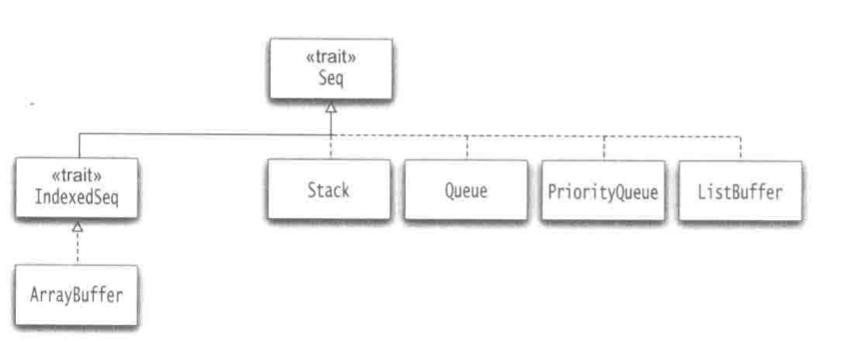
上图展示了Scala中的可变序列。
列表
在Scala中,列表类似数据结构链表,列表要么是Nil,空表。要么是提供head元素加一个tail,而tail又是一个列表
1 | |
::操作符从给定的头和尾创建一个新的列表
1 | |
除了用迭代器遍历链表,Scala中使用递归更好
1 | |
还可以用模式匹配来遍历
1 | |
对于sum,Scala已经提供了直接list.sum即可
如果想修改可变列表里的元素,可以用ListBuffer,这是一个由链表支持的数据结构,包含一个指向最后一个节点的引用。因此可以高效的从任意一端增减元素。
改变列表元素是低效的,最佳选择是用结果生成一个新的列表。
集
集是不重复元素的集合,尝试将已有元素加入是无效的。
集不保留元素的插入顺序,默认情况下,集以哈希集实现。元素根据hashCode的值进行组织。Scala和Java一样,每个对象都有hashCode方法。
链式哈希集可以记住元素被插入的顺序,它会维护一个链表来达到这个目的
1 | |
位组是集的一种特殊实现,用一个字位序列的形式存放非负整数,如果位组中第i位是1,说明i在这个集中。Scala提供了可变和不可变两种BitSet
contains方法检查元素是否存在,subsetOf方法检查某个集是否是另一个的子集。
union,intersect和diff方法也有
1 | |
用于添加或去除元素的操作符
不同类型的集合对应不同的操作符
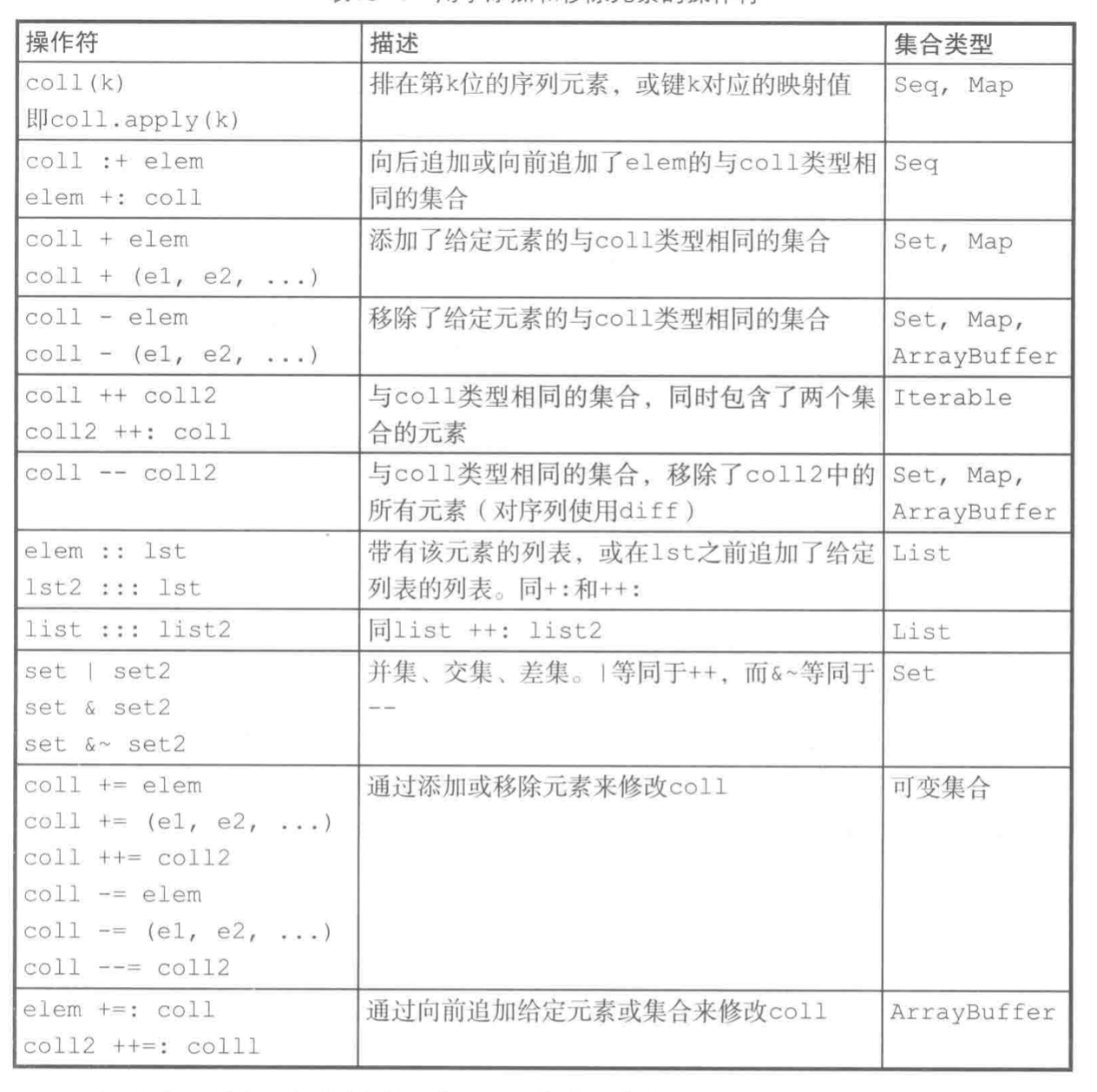
+用于将元素添加到无先后次序的集合
+:和:+ 用于添加到有序集合到头尾
这些操作符都返回新集合
可变集合有+=来进行操作
不可变集合可以在var上使用+=或:+=
1 | |
常用方法
Iterable特质常用的方法如下:

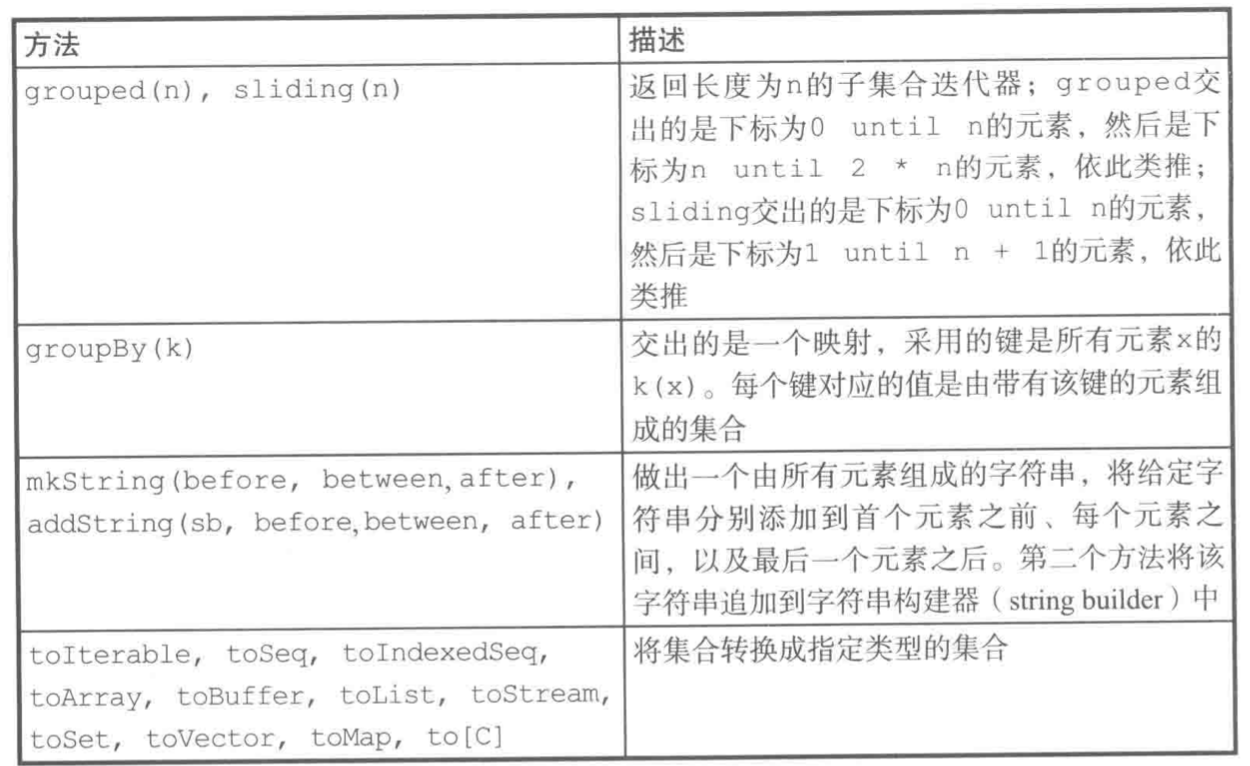
seq多出了如下常用方法:


这些方法不改变原有集合,它们返回一个和原有集合相同类型的新集合,这被称为统一返回类型原则。
将函数映射到集合
对集合中的所有元素进行操作,可以用map方法
1 | |
如果传入的映射函数是一个输入,多个输出,则可以用faltMap将结果转为一个集合
1 | |
transform方法是map的等效操作,只不过当场执行而不是交出新的集合。应用于可变集合,将每个元素替换为转换后的。
groupBy方法交出一个映射,键是函数求值后的值,值是函数求值得到给定键的元素的集合。
1 | |
化简、折叠和扫描
用二元函数来组合集合中的元素,如
1 | |
利用这种二元函数的操作,可以实现一些统计的功能,比如统计集合中元素出现的频率,这就是折叠
1 | |
拉链操作
当存在两个集合,想将其中对应的元素结合在一起时,可以用拉链操作
比如将商品和价格两个集合结合起来
1 | |
之后可以调用map等函数对每一个数对进行操作
如果两个集合长度不同,zip结果中舍弃长集合多出来的值
zipAll方法可以指定短集合的默认值
迭代器
对于之前map等操作无法满足的场景,也可以使用迭代器调用next方法获取每一个元素
1 | |
如果想查看下一个元素,又不想移动迭代器指针,用buffered方法转化迭代器成为BufferedIterator,head方法用于获取下一个元素但不移动指针。
流
流是一个尾部被懒计算的不可变列表,只有当需要时才会被计算
1 | |
懒视图
对集合应用view方法实现懒加载,该方法交出一个总是被懒执行的集合
1 | |
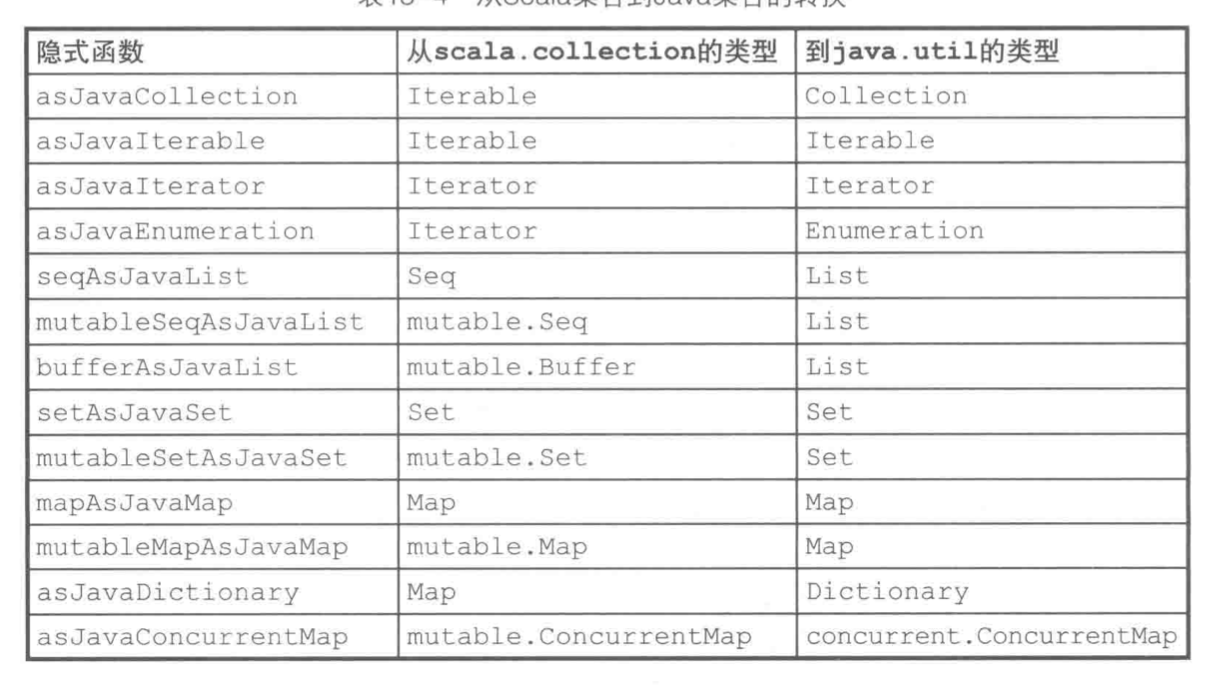
与Java集合的互操作
JavaConversions 对象提供了Scala和java集合之间转换的一组方法

并行集合
scala 对并发求值提供了很好的支持,类似mapreduce,通过并行的操作提高效率。
1 | |