文法
文法指一组用于产出所有遵循某个特定结构的字符串的规则。比如回文字符串可以用规则定义出
- 字符串的第i个字符和第len-i-1个字符相同(从0开始算)
文法通常以一种被称为巴科斯范式(BNF)的表示法编写。
可以通过文法来定义数学表达式,第一步被称为词法分析,在此列中词法分析会收集数字。
更一般的,词法分析会丢掉空白和注释并新城词法单元(标识符,数字或符号)。
组合解析器操作
为了使用Scala解析库,需要提供一个扩展自parsers特质的类并定义那些由基本操作组合起来的解析操作,基本操作包括:
- 匹配一个词法单元
- 在两个操作之间选择 |
- 依次执行两个操作 ~
- 重复一个操作 rep
- 可选择的执行一个操作 opt
如下这个解析器可以识别算数表达式,扩展自RegexParsers,可以用正则表达式来匹配词法单元。
1
2
3
4
5
6
| class ExprParser extends PegexParsers{
val number = "[0-9]+".r
def expr: Parset[Any] = term - opt(("+"|"-")~ expr)
def term: Parser[Any] = factor ~ rep("*" ~ factor)
def factor: Parser[Any] = number | "(" ~ expr ~ ")"
}
|
可以调用继承下来的parser方法来运行该解析器
1
2
3
| val parser = new ExprParser
val result = parser.parser.parseAll(parser.expr,"3+3+2")
if(result.successful) println(result.get)
|
解析器结果变换
可以将解析器的中间输出变换成有用的形式。
1
2
3
4
5
| def factor:Parser[Any] = number | "(" ~expr ~ ")"
def factor:Parser[Int] = number ^^ {_.toInt} | ...
|
丢弃词法单元
对于解析来说,词法单元是必须的,但在匹配之后则通常可以丢弃。> 和 <操作符用来丢弃词法单元。
““~>factor的结果只是factor的计算结果,而不是”“~f的值。可以将term函数简化为:
1
2
3
| def term = factor ~ rep("*" ~> factor) ^^ {
case f~r => f*r.product
}
|
> 和 <操作符指向被保留下来的部分。
生成解析树
当你构建解析器或编译器的时候,会想要构建出一棵解析树,这通常用样例类来实现。如下类表达一个算数表达式
1
2
3
| class Expr
case class Number(value:Int) extends Expr
case class Operator(op:String, left:Expr, right:Expr) extends Expr
|
解析器会将3+4*5变成如下样子:
1
| Operator("+",Number(3),Operator("*",Number(4),Number(5)))
|
解析器会计算改表达式的值。编译器会生成代码。
要生成解析树,需要用^^操作符带上交出树节点的函数。
1
2
3
4
5
6
7
8
9
| class ExprParser extends RegexParsers{
...
def term: Parser[Expr] = (factor ~ opt("*"->term)) ^^{
case a ~ None => a
case a ~ Some(b) => Operator("*", a, b)
}
def factor: Parser[Expr] = whileNumber ^^ (n => Number(n.toInt)) |
"(" ~> expr <~ ")"
}
|
避免左递归
如果解析器函数在解析输入之前就掉用自己的话,就会一直递归下去。比如:
1
| def ones: Parser[Any] = one ~ "1" |"1"
|
这样的函数被称为左递归,要避免,可以重新表述一下文法。
1
| def ones: Parser[Any] = "1" ~ ones |"1"
|
更多的组合子
rep 方法匹配零个或多个重复项,下表展示其不同变种。
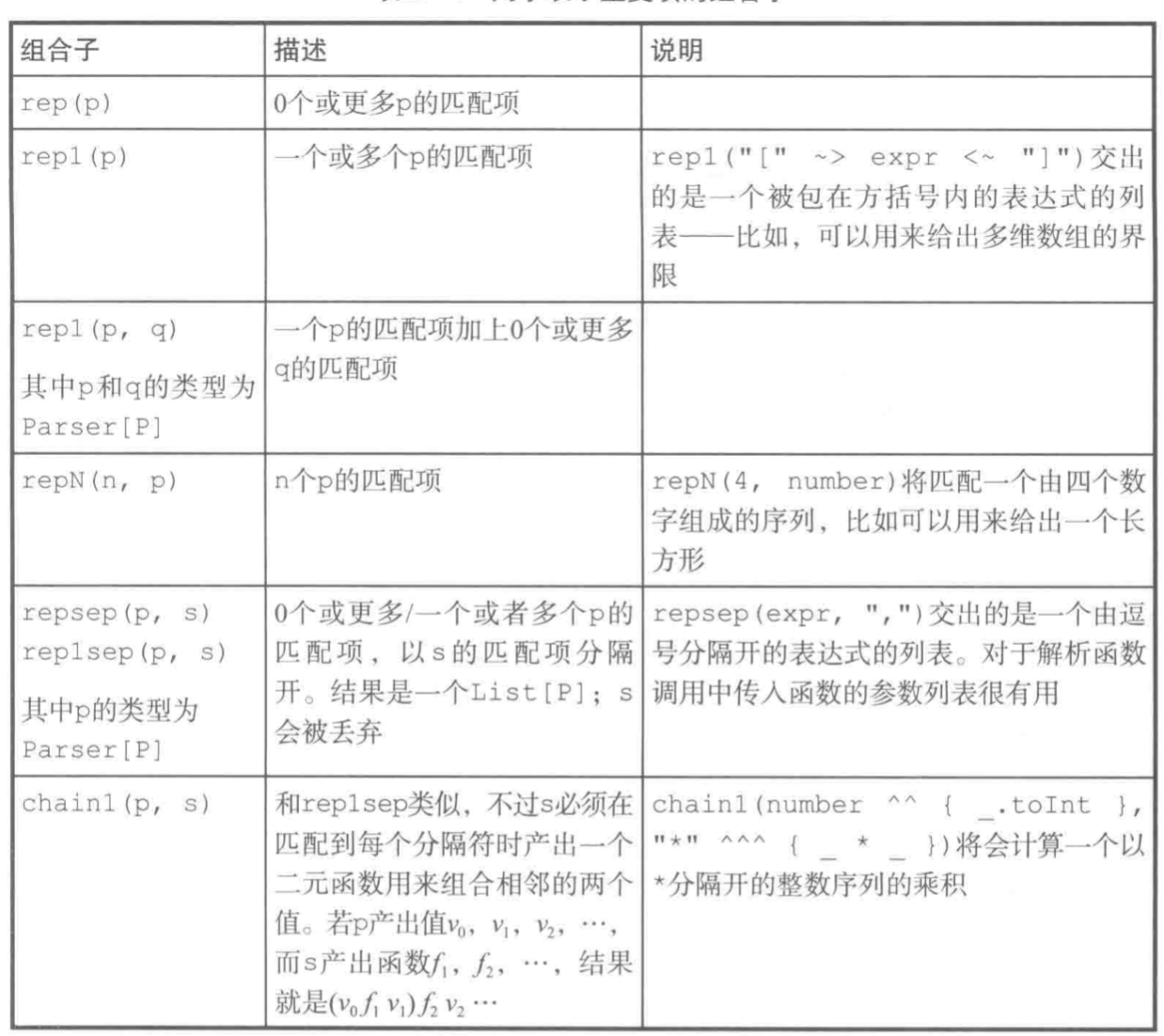
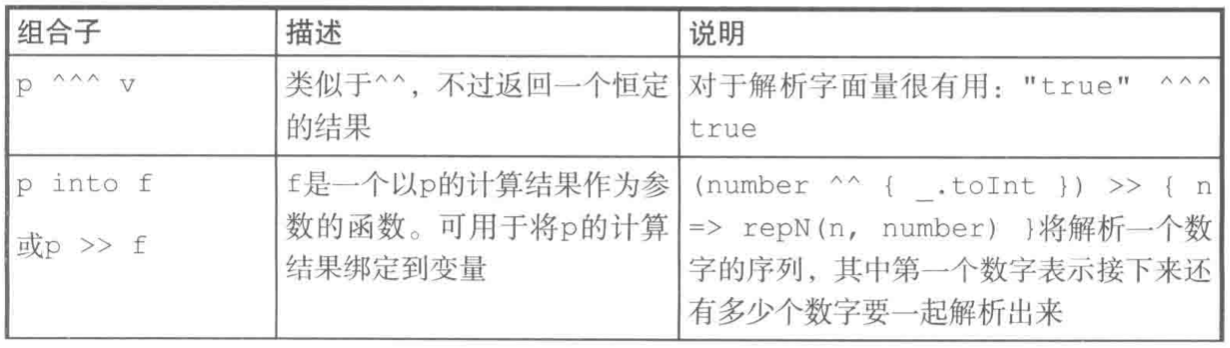
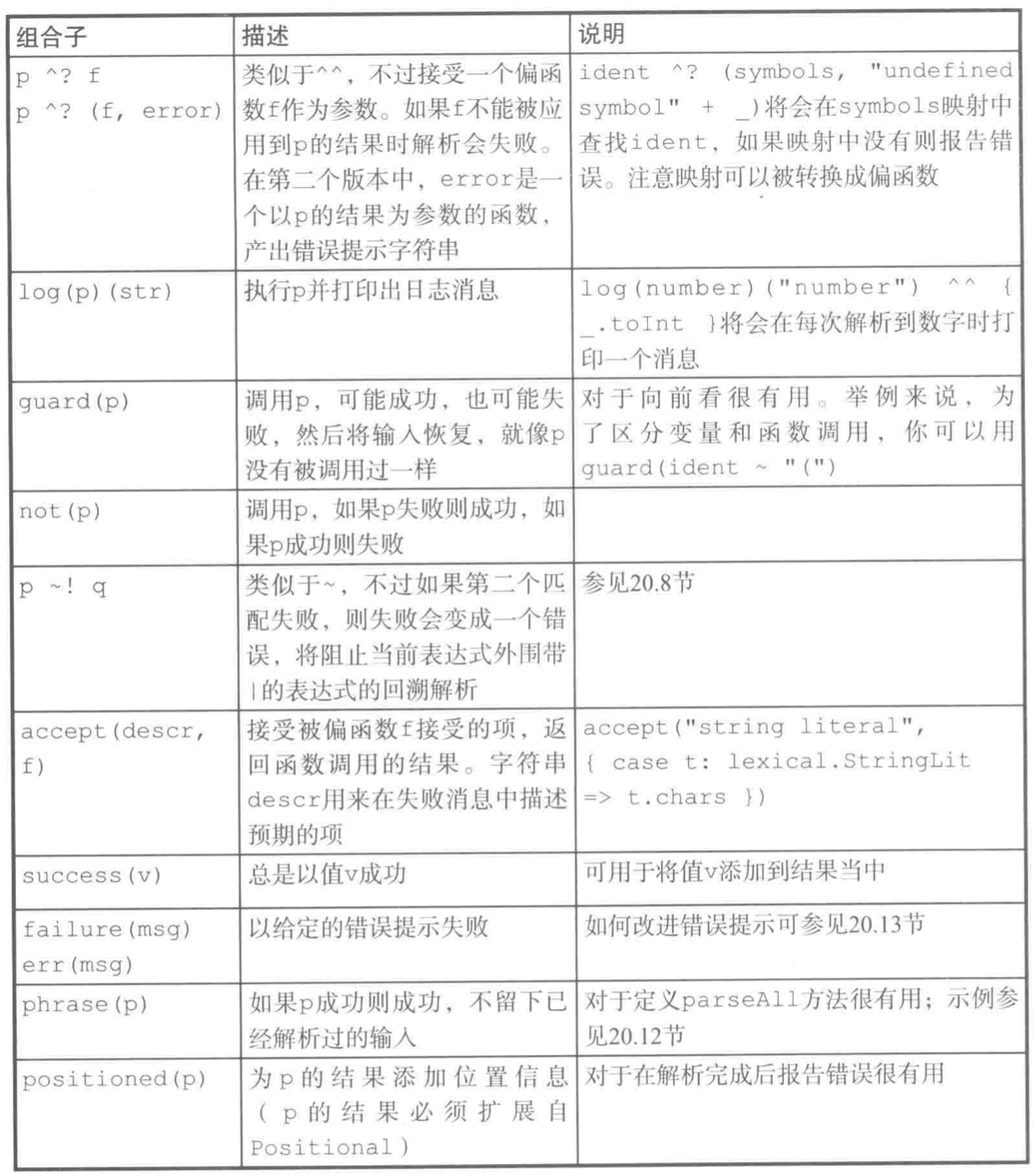
一个以逗号分隔的数字列表可以定义为:
1
| def numberList = number ~rep("," ~> number)
|
避免回溯
每当二选一的p|q,q被解析而p失败时,解析器会用同样对输入尝试q,这样的机制称为回溯。回溯机制同样发生在opt或rep中出现失败的时候。
1
2
3
| def expr: Parser[Any] = term ~("+"|"-")~ expr | term
def term: Parser[Any] = factor ~ "*" ~ term | factor
def factor: Parser[Any] = "(" ~ expr ~ ")" | number
|
上述解析器会造成回溯。
记忆式解析器
记忆式解析器使用一个高效的解析算法,该算法会捕获到之前的解析结果这样的好处是:
- 解析时间可以确保与输入长度成比例关系
- 解析器可接受左递归的语法
解析器说到底是什么
从技术上讲,Parser[T]是一个带有单个参数的函数,参数类型为Reader[Elem],而返回值的类型为ParseResult[T]。
正则解析器
RegexParsers 特质在目前为止的所有解析器事例中都用到了,它提供两个用于定义解析器的隐式转换:
- literal 从一个字符串字面量做出一个Parser[String]
- regex从一个正则表达式做出一个Parser[String]
基于词法单元的解析器
基于词法单元的解析器使用Reader[Token] 而不是Reader[Char]。stdTokens子特质定义了四种在解析编程语言时经常遇到的词法单元
- Identifier 标识符
- Keyword 关键字
- NumericLit 数值字面量
- StringLit 字符串字面量
错误处理
当解析器不能接受某个输入时,解析器会生产一个错误提示,描述解析器在某个位置无法继续了。如果有多个失败点,最后访问到的那个将被报告。