前缀树
基本概念
前缀和算法用于快速搜索文本中出现过的关键词,比如给你一个词,让你判断这个词在某篇文章中是否出现过,或者这个词的前缀是否出现过等等。可以应用在自动补全和拼写检查等领域内。文本数据库ElasticSearch也适用这种结构来存储数据。
算法的基本想法如下,要想快速搜索单词,将树和哈希字典结合将是不二选择。考虑如下数据结构,一棵树的每一个节点都是一个哈希字典,字典的key是字母,字典的value是这个字母后续可能字母的节点。
举例如下,比如我有一个字典树,存入了单词apple, apps, book, app,则它应该长这样
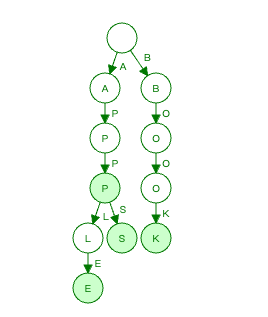
可以看到,每个节点表示一个字母,节点的子节点表示单词后面一个字母。一个节点的所有子节点被存在同一个hasmap里。另外还要注意,节点除了hashmap来存自己的子节点外,还有一个标记值来表示自己是不是一个单词的结尾。(绿色的节点表示到此为止已经是一个单词了)
基础实现
对于前缀树这种结构,一般需要实现如下几个方法
- 插入新的单词
- 查找某个单词是否存在
- 查找某个前缀是否存在
- 删除某个单词(进阶):递归的做,查找当前字母是否在当前节点里面。如果不在退出就行,如果在且这是最后一个字母,则先改结尾标志,再看能否删除这个节点(这个节点没有子节点了)如果在,递归向下,看下一个字母和下一个节点。递归调用退出后,判断下当前节点的子节点是否为空,如果为空,则删除这个节点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94class TrieNode { // 节点
boolean isWord;
TrieNode[] children = new TrieNode[26];
}
class Trie {
TrieNode root; // 根节点
public Trie() {
root = new TrieNode(); // 构造字典树,就是先构造出一个空的根节点
}
//【向字典树插入单词word】
// 思路:按照word的字符,从根节点开始,一直向下走:
// 如果遇到null,就new出新节点;如果节点已经存在,cur顺着往下走就可以
public void insert(String word) {
TrieNode cur = root; // 先指向根节点
for (int i = 0; i < word.length(); i++) { // 如果是【后缀树】而不是【前缀树】,把单词倒着插就可以了,即for(len-1; 0; i--)
int c = word.charAt(i) - 'a'; // (关键) 将一个字符用数字表示出来,并作为下标
if (cur.children[c] == null) {
cur.children[c] = new TrieNode();
}
cur = cur.children[c];
}
cur.isWord = true; // 一个单词插入完毕,此时cur指向的节点即为一个单词的结尾
}
//【判断一个单词word是否完整存在于字典树中】
// 思路:cur从根节点开始,按照word的字符一直尝试向下走:
// 如果走到了null,说明这个word不是前缀树的任何一条路径,返回false;
// 如果按照word顺利的走完,就要判断此时cur是否为单词尾端:如果是,返回true;如果不是,说明word仅仅是一个前缀,并不完整,返回false
public boolean search(String word) {
TrieNode cur = root;
for (int i = 0; i < word.length(); i++) {
int c = word.charAt(i) - 'a';
if (cur.children[c] == null) {
return false;
}
cur = cur.children[c];
}
return cur.isWord;
}
//【判断一个单词word是否是字典树中的前缀】
// 思路:和sesrch方法一样,根据word从根节点开始一直尝试向下走:
// 如果遇到null了,说明这个word不是前缀树的任何一条路径,返回false;
// 如果安全走完了,直接返回true就行了———我们并不关心此事cur是不是末尾(isWord)
public boolean startsWith(String word) {
TrieNode cur = root;
for (int i = 0; i < word.length(); i++) {
int c = word.charAt(i) - 'a';
if (cur.children[c] == null) {
return false;
}
cur = cur.children[c];
}
return true;
}
// Returns true if root has no children, else false
static boolean isEmpty(TrieNode root) {
for (int i = 0; i < 26; i++)
if (root.children[i] != null)
return false;
return true;
}
// Recursive function to delete a key from given Trie
static TrieNode remove(TrieNode root, String key, int depth) {
// If tree is empty
if (root == null)
return null;
// If last character of key is being processed
if (depth == key.length()) {
// This node is no more end of word after
// removal of given key
if (root.isWord)
root.isWord = false;
// If given is not prefix of any other word
if (isEmpty(root)) {
root = null;
}
return root;
}
// If not last character, recur for the child
// obtained using ASCII value
int index = key.charAt(depth) - 'a';
root.children[index] =
remove(root.children[index], key, depth + 1);
// If root does not have any child (its only child got
// deleted), and it is not end of another word.
if (isEmpty(root) && !root.isWord) {
root = null;
}
return root;
}
}实现细节
除了删除的方法外,不需要用递归来做(虽然递归也能做出来),直接顺序向下遍历这个树就行。
删除的方法需要递归,因为要从下往上删除节点。(这里悟一下递归的真谛,自己调用自己只是递归的表象,递归的本质是我需要用到我下面的处理结果)
此处默认是英文字典树,则字典用26位的数组就行,不需要hashmap
进阶情况
lc208
是前缀树的基础实现,后续补充其他用法
lc820 单词压缩,利用字典树的构造过程——忽略后缀单词
lc211 通配符字典树, 含有通配符的字典树匹配——递归的search
lc676 魔法字典,允许且必须变化一个字符后再匹配——递归的search
参考资料
前缀树
http://www.bake-data.com/2024/03/31/前缀树/