Flink基础五篇-1-流处理基本概念
Dataflow图
描述数据如何在不同操作之间流动,是一个有向无环图。图中的顶点称为算子,表示计算,边表示数据依赖关系。
其中没有输入端端算子是数据源(source),代表数据读取。没有输出端的算子是数据汇(sink),代表数据最终的输出。
算子
代表对数据的操作,一种操作可以抽象为一个算子。比如读取数据,筛选数据,计算数据的平均值。输出数据等。
算子任务
算子代表一种操作,而大数据量下往往会有多个任务同时进行这种操作,这里每一个对部分数据进行具体操作的就是算子任务。
逻辑Dataflow图
是高层视角下的计算逻辑,包含多个算子,不会考虑具体的并行度。

物理Dataflow图
具体执行流式任务时,会将逻辑执行图转换为物理执行图,区别在于,物理执行图包含了每个算子的并行度信息,即不以算子而是以算子任务的形式进行展示。
对于并行度不为1的算子,物理执行图能够表示出不同算子任务之间数据交换的策略
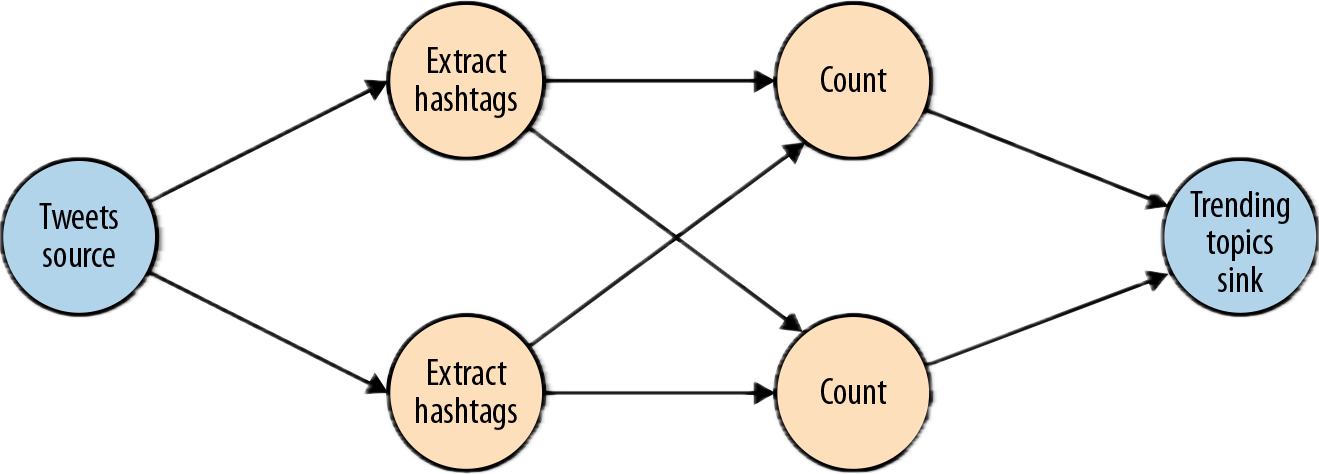
数据并行和任务并行
数据并行:指的是将数据分成不同的部分,让进行同一个操作的多个任务分别去处理不同的部分。
任务并行:指的是让不同算子的任务(基于相同或者不同的数据)并行计算。
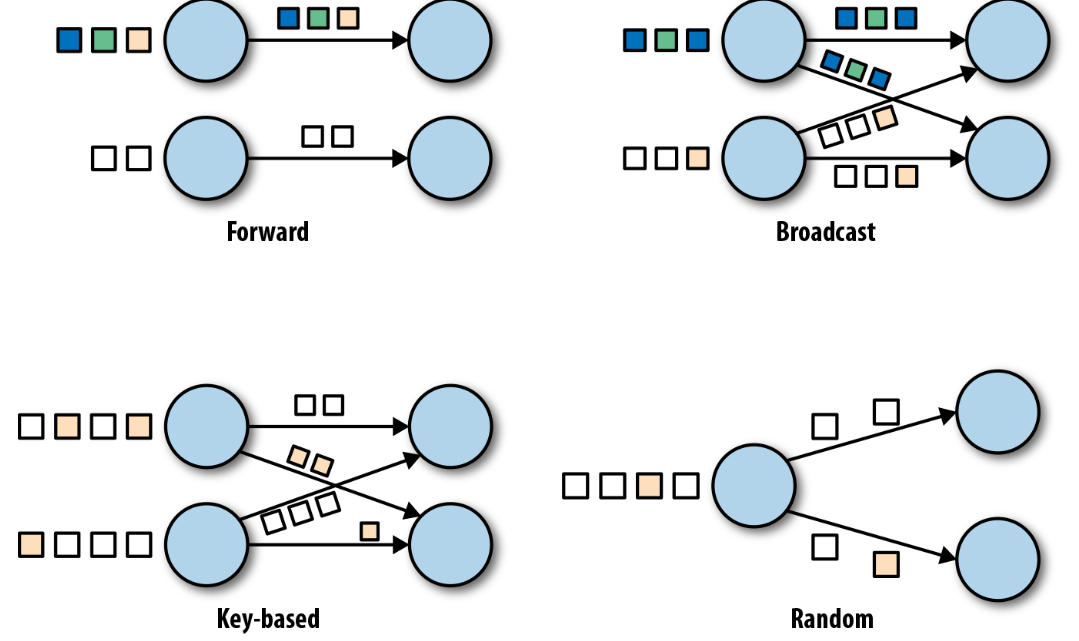
数据交换策略
不同算子任务之间,数据有三种交换策略:
- 广播:当前算子任务将结果发送给下游每一个算子任务
- 转发:上下游的任务之间有一一对应的关系,数据直接进行传递
- 基于键值:上有根据分组条件,将数据推送到不同的下游
- 随机:上游随机将数据推送到下游
延迟和吞吐
延迟:延迟就是从接收到数据到输出数据的时间间隔
吞吐:吞吐指系统每单位时间能处理的数据条数
通过上文提到的数据并行,可以在处理更多事件的同时降低延迟。
有状态操作和无状态操作
有状态操作或称有状态算子,指当前对数据的操作需要依赖已处理的事件。有状态算子需要维护之前接收的事件信息。并且根据传入的事件更新状态,用于未来的事件处理。
无状态算子无需依赖已处理的事件。
滚动聚合
是有状态的算子,根据每个到来的事件持续更新结果。如求和,求平均等。为了更有效的合并事件和当前状态并生成新的结果,聚合函数必须满足可结合和可交换的条件。否则状态的保存需要保存整个事件列表。
窗口操作
窗口操作会持续创建一些称为桶的有限事件集合,允许我们基于这些有限集进行计算。事件会根据其时间或者其他属性分配到不同的桶中。
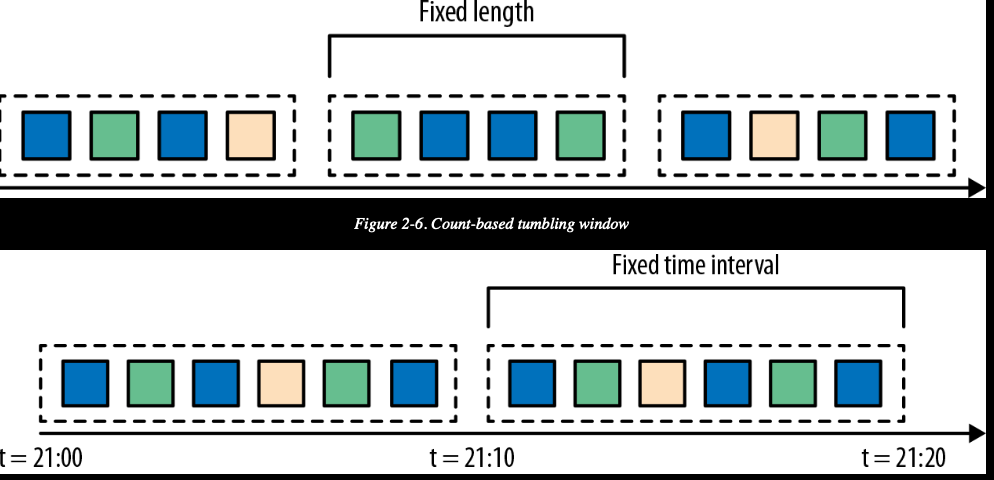
滚动窗口
将事件分配到长度固定且不重合的桶中。在窗口边界通过后,所有事件会发送给计算函数进行处理。
基于数量的滚动窗口定义了在触发计算前需要集齐多少个事件。
基于时间的滚动窗口定义了在桶中的缓冲数据的时间间隔。
举例:每20条数据进行一次计算。每10s进行一次计算。
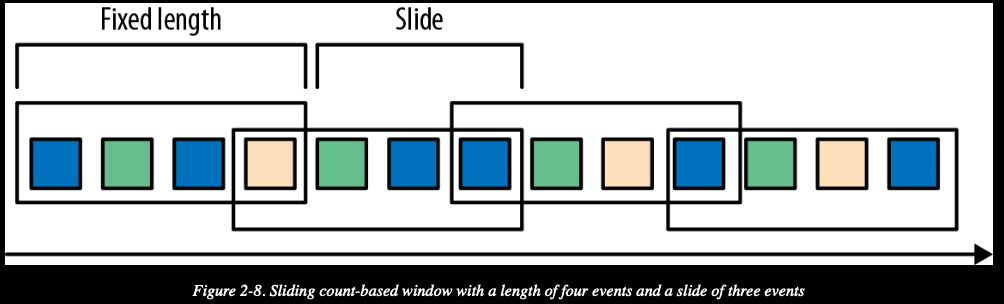
滑动窗口
将事件分配给大小固定且可以重合的桶中。每个事件可能属于多个桶。通过指定长度和滑动间隔来定义窗口。滑动间隔决定每隔多久生成一个新的桶。
比如每次滑动三个事件,每个窗口内包含4个事件
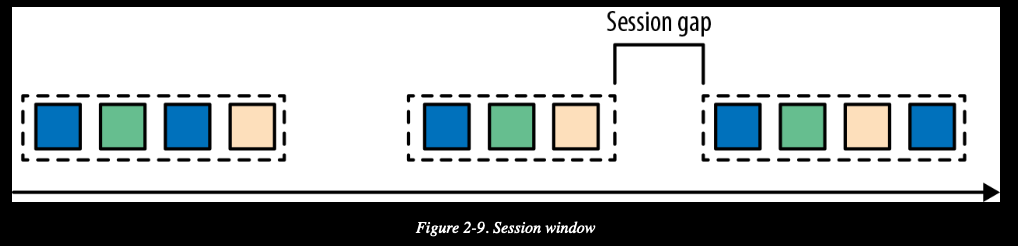
会话窗口
把事件按照用户的行为或者会话来源进行分组。来自于同一个用户的一次活动的数据分入一个桶内。会话由发生在相邻时间内的一系列事件外加一段非活动时间组成。会话窗口需要定义一个会话间隔,这个值表示非活动时间的市场,即如果没有事件的时间超过这个值,那后续来的事件就属于新的会话桶了。
时间语义
处理时间
处理时间是指数据被系统接收到开始处理的事件
事件时间
事件时间指这个事件真实发生的时间
对同一条数据,处理时间一定晚于事件时间。如果按照事件时间来处理,则处理逻辑一定和发生顺序一致。如果按处理时间处理,则会出现早发生但晚到达的数据被晚处理。
水位线
水位线是一个全局的进度指标,当处理算子收到一个水位线T后,表示当前算子可以确信不会有比这个水位线更早的数据到来了(不会有时间戳<=T的数据了),可以关闭之前的窗口,进行运算了。
水位线允许我们在准确性和时效性之前做权衡。
状态一致性模型
有状态算子需要基于状态进行计算。这就涉及到了状态的存储,管理,划分,恢复等等。成熟的流处理引擎一定要有完善的状态管理机制,保证在任何情况下的状态一致。
tips: flink使用tcp连接
结果保障
至多一次
在出现异常到异常恢复的过程中,数据被处理过至多一次。这表示发生故障时事件可以被丢弃。
至少一次
表示在异常恢复的过程中,事件至少被处理过一次,不会丢弃数据,但是一条数据可能被处理多次。
精确一次
表示在异常恢复的过程中,事件只能被处理一次。
flink内部采用了轻量级的检查点机制来实现精确一次的结果保障。但根据输入和输出的不同特性,最终能支持的结果保障也不同。
要想实现端到端的精确一次,需要输入和输入端都支持事务或者幂等操作。后面会详细讨论。