Flink基础5篇-3-DataStreamAPI
Flink流式应用典型步骤
1 | |
读取输入流
1 | |
应用转换

执行
1 | |
Flink程序是延迟计算的方式执行的。创建和转换操作的API调用不会立即执行,而是在执行环境中构建一个执行计划,计划中包含了从创建环境到数据转换到数据输出的步骤。只有在调用execute方法时,系统才会触发程序执行。
构建完成的计划会被转换为JobGraph提交给JM执行。
转换操作
DataStreamAPI中的转换操作可以分为4类
对单条记录进行修改
map
filter
flatmap
基于keyedStream的转换
keyby
滚动聚合:将生成一个包含聚合结果的DataStream,每当有新记录到来,会更新聚合结果
union:将两条流合并成一条,合并记录遵循FIFO,类型相同的流合并为一个

connect:类型不同的两个流合并成一个

coMap,coFlatMap:是连接后的流(connectedStreams)提供的方法,将来自流1和流2的两种类型的元素转换为一个输出

Splict,Select:将一个输入流分割成两条或多条,每个事件可以被分发到另个或多个流

分发转换
之前提到过Flink的数据交换策略,这决定了上下游算子的多个任务之间如何进行数据交换。
默认情况下Flink会根据并行度和操作语意自行决定交换策略。但有时候我们需要自定义,避免数据倾斜等问题。下面是几种分发策略指定的方法
- 随机:用DataStream.shuffle()方法进行。该方法按照均匀分布随机将数据发送给下游算子的并行任务
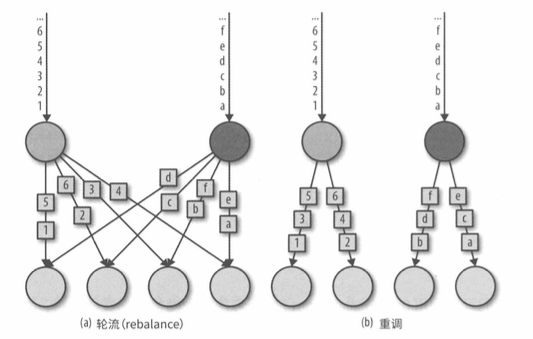
- DataStream.rebalence(),会轮流发送给下游算子并行任务
- rescale(),也是轮流发送,但分发目标仅限于部分后继任务。上下游并行度不等的情况下的一种轻量级负载均衡。下游比上游越多越有效。
r e b a l a n c e () 和 r e s c a l e () 的 本 质 不 同 体 现 在 生 成 任 务 连 接 的 方 式 。 r e b a l a n c e () 会 在 所 有 发 送 任 务 和 接 收 任 务 之 间 建 立 通 信 通 道 ; 而 r e s c a l e () 中 每 个 发 送 任 务 只 会 和 下 游 算 子 的 部 分 任 务 建 立 通 道
并行度可以在执行环境级别和单个算子级别进行控制。默认所有算子并行度都是执行环境并行度。

类型
支持的数据类型
Flink支持java和scala所有常见数据类型,使用最多的可分为下面几类
- 原始类型:int,string,boolean,double,float等
- java和scala等元组:Tuple2[String,String]
- scala样例类 case class Person(name:Stirng,age:Int)
- POJO: 一个public的,有无参构造器的,所有字段有get和set方法的类
- 特殊类型
实现函数
函数类
Flink中所有自定义函数的接口都是以接口或者抽象类的形式暴露的。
可以通过实现接口或继承抽象类的方式实现自定义函数。

随后可将函数类的实例传递给fliter转换

匿名类也可以
¥

注意:函数必须是java可序列化的
还可以使用lambda函数
富函数
如果需要在处理第一条数据之前进行初始化,或者需要函数执行的上下文,则实现富函数。
在使用富函数时,可以对函数的生命周期实现两个额外方法:
- open:初始化方法,在每个任务首次调用前调用一次
- close:在每个任务最后一次调用后调用一次
此外,利用getRuntimeContext()获取执行上下文,如并行度,任务编号,任务名称等。


导入外部依赖
使用maven或sbt进行依赖的导入
推荐使用fat jar的形式,把所有依赖打入一个jar包