Spark基础-结构化API和操作
DataFrame和DataSet共同点
具有行和列的类似于数据表的集合类型,所有列的行数相同,缺省值用null填充。每一列的所有行数据类型相同。
DataFrame
是非类型化的,列的数据类型由spark维护,在运行时检查类型。
可以将DataFrame看作是Row类型的DataSet
Dataset
是类型化的,仅支持基于JVM的语言,通过case class或Java beans指定类型。在编译时进行类型检查。
使用Dataset API时,将Spark Row格式的每一行转换成指定的特定类型对象(case或bean),转换会减慢操作速度,但提供更大灵活性。

上图将DF转成了DS
SQL
直接用SQL实现spark任务
托管表
简单理解就是由spark管理的表,不光包括数据,还包括表的元数据,都是spark的格式存储的。比如df调用saveAsTable生成的结果。
非托管表
spark读取到的数据都可以看成是一张非托管表,这些数据以其他格式和方式存在,spark只读取使用,不进行管理。
执行过程
- 编写结构化API代码
- spark将其转换为逻辑执行计划
- spark将逻辑执行计划转换为物理执行计划
- spark在集群上执行物理计划(RDD操作)
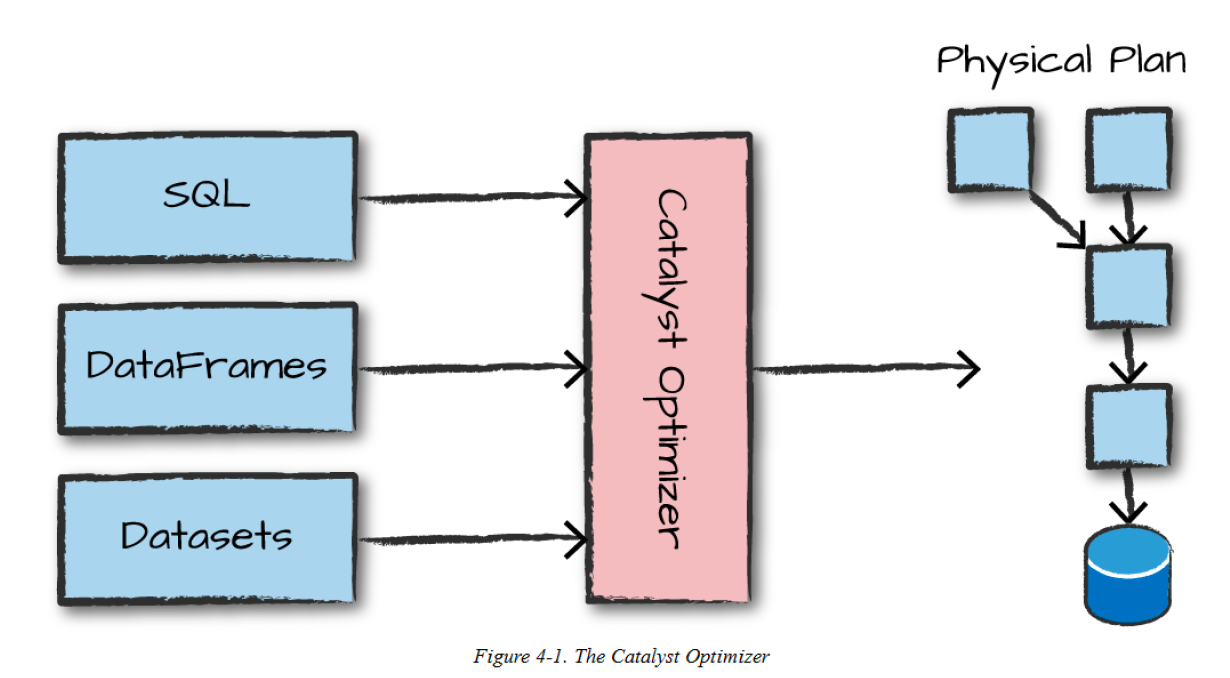
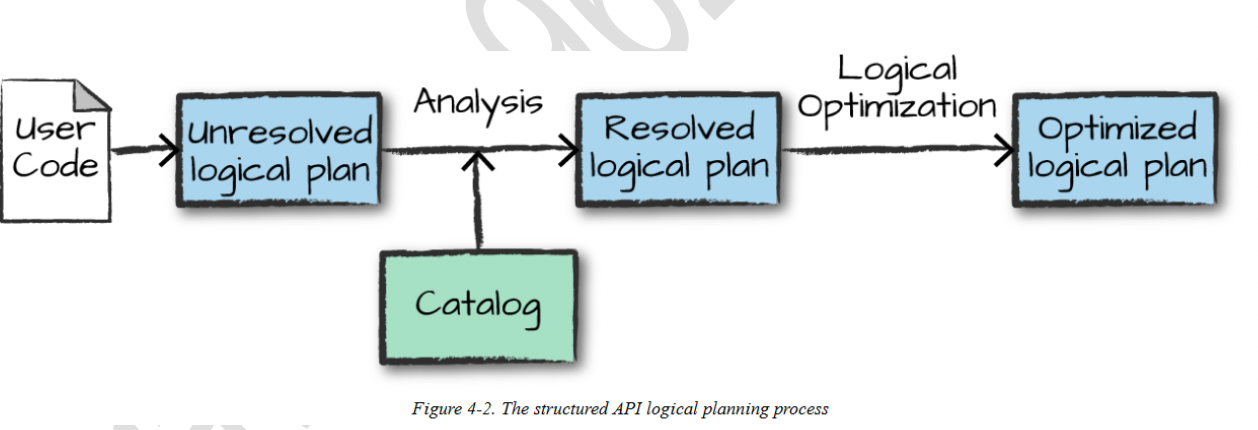
下图表示代码到逻辑执行计划的转换流程,主要包括逻辑计划的转换和catalyst优化器优化两个部分
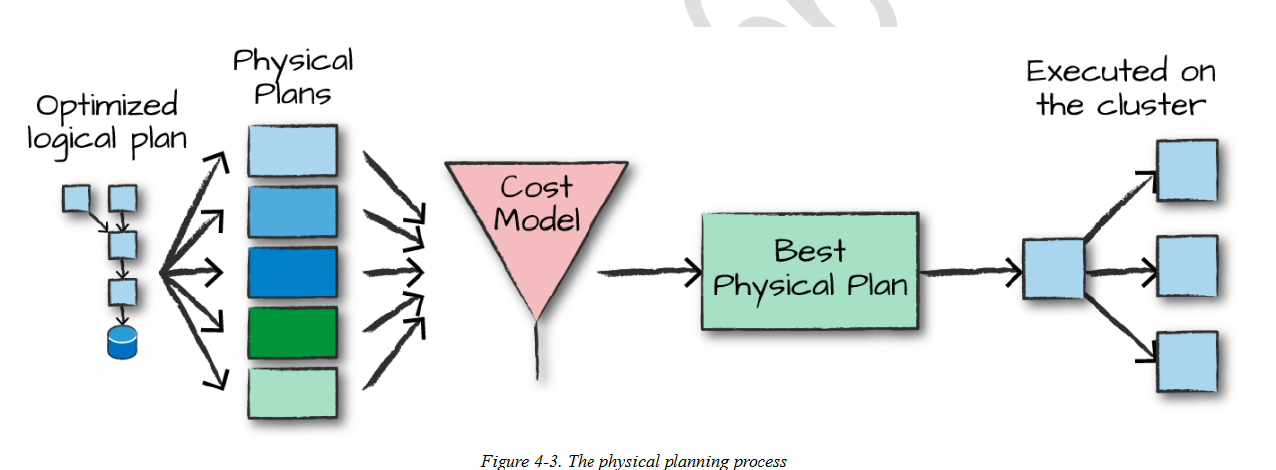
物理计划通过生成不同的物理执行策略,并通过代价模型进行比较分析,从而指定如何在集群上执行逻辑计划。
重分区
用df的repartition方法进行数据的重分区,会导致数据的shuffle,一般有两个参数(可以都传)
- 改变分区个数repartion(10)
- 按某列分区repartion(col(“aaa”))
如果要按照某一列进行大量操作,则按这一列重分区很有必要
合并操作
coalesce操作,不会导致shuffle,但会尝试合并分区
1 | |
驱动器获取行
将各个executor数据收集到driver上。collect函数从整个df中获取数据到driver
1 | |
空值的处理
建议使用null来表示DataFrame中的空值,其他的空如空字符串,scala的None,都不被spark认为是空值。
drop默认删除包含null的行
Coalesce方法从一列中选择第一个非空值
数组处理
split:将一列的值分割为数组
size:长度
array_contains:包含
explode:行转多行,数组中每个值变成一行,其他列重复
自定义函数UDF
spark在driver上序列化udf,将它网络传输到所有executor
udf会导致性能下降,无法参与优化
聚合操作
spark允许下列分组类型:
- group by 对一个或多个列执行指定的聚合函数
- window:开窗操作,支持聚合一定范围内的值
- grouping set:多个不同级别进行聚合(SQL中使用,dataFrame中对应rollup和cube)
- rollup:聚合后针对指定的多个key进行分级分组汇总
- cube:聚合后针对指定的多个key进行全组合分组汇总
window
比如计算最近7天平均值
通过一个窗口,决定哪些行传递给聚合函数
定义窗口:


使用窗口

分组集
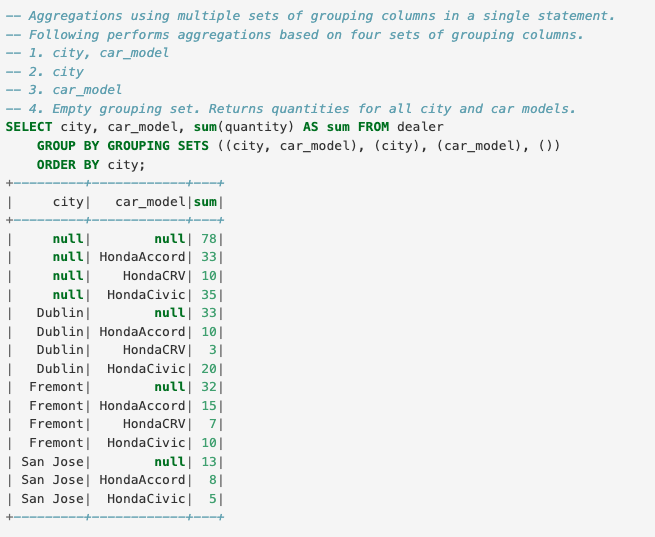
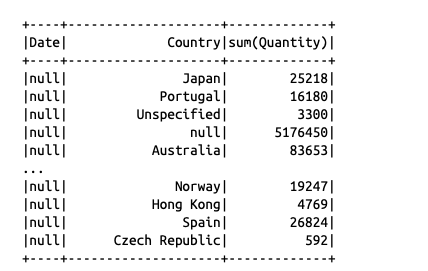
支持跨多个组的聚合操作。(仅在SQL中可用),将各种分组的统计的结果union到一起。
比如下面的例子,表示先按照city和car_model分组统计,再按照city统计,再按照car_model统计,再按照全部统计,将所有统计结果union
rollup
rollup操作在df和ds上使用,效果和上面的grouping sets一样,即可以指定多个聚合维度,最终把这些聚合维度下的数据union起来

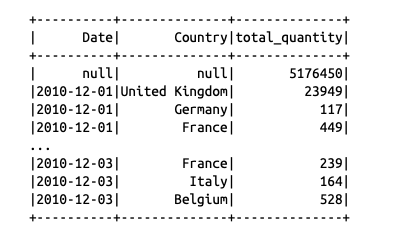
cube
cube是更进一步的操作,不需要知道聚合组合的指定,直接对所有参与列值进行所有维度的全组合聚合。比如下面,指定了两个列,则一共有4种可能的组合

join操作
join种类
join的类型有很多,比如inner join, outer join, left join, right join等区别在于如何处理没有匹配上的行。这里不再赘述。
join执行过程
根据表的大小不同,spark采取不同的join方式。总共3种
broadcast hash join
当两张表中有一张很小的时候,采用广播的方式将小表广播到所有executor,避免了all-to-all的shuffle join。发送成功后,对小表的连接字段做hash存储,然后对大表的每条数据进行验证,看能否匹配。
shuffle hash join
当小表不足以广播但仍旧不太大时,可以根据join key相同必然分区相同的原理,将两张表分别按照join key进行重新组织分区,然后做hash join
sort merge join
两张大表进行关联时,不再用hash的形式,因为需要额外内存存储生成的hash,大表情况下内存可能不足。改用sort merge join。
首先还是按照join key进行重新组织分区,之后在每个executor上,对两表的数据分别排序,之后进行两个有序列表的merge。
总结
大表与一个很小的表关联,采用broadcast hash join
大表和一个小表关联,选择shuffle hash join
大表和大表关联,采用sort merge join