Spark基础-低级非结构化API
低级API
有两种低级API
处理分布式数据(RDD)
用于分发和处理分布式共享变量(广播变量和累加器)
使用时机
当高级API不满足需求时,比如对集群中数据的物理存储进行非常严格的操作
需要维护遗留的旧版本代码时
需要执行一些自定义共享变量操作时
RDD(弹性分布式数据集)
RDD是一个只读不可变的且已经分块的记录合集,可以被并行处理。RDD中记录的仅仅是对应的Java,scala或python对象。可以以任何格式在这些对象中存储任何内容。
RDD类型
每个RDD包含以下5个主要内部属性
- 数据分片列表
- 作用在每个数据分片的计算函数
- 描述与其他RDD的依赖关系列表
- (可选)为key-value RDD配置的分片方法
- (可选)优先位置列表,根据本地数据特性,指定了每个分片的处理位置偏好(如HDFS文件,这个列表就是每个文件块所在的节点)
创建RDD
利用df或者ds的rdd方法就能转换为rdd


RDD也可以转换会df或ds

通过spark上下文读取文件,读取结果将生成一个RDD

操作RDD
RDD操作的是原始的Java/Scala对象而非Spark类型,还缺乏辅助方法和函数。因此所有的filter,map等方法都必须自定义。
比如定义一个filter操作:


保存文件
Spark会把RDD中每个分区都读出来,并写到指定位置中。

mapPartitions
mapPartitions函数每次处理一个数据分区(可以通过迭代器遍历这个分区的数据)。

foreachpartitions
foreachpartitions没有返回值,仅用于迭代所有数据分区,用于写入数据库等不需要返回值的操作。
高级RDD操作
key-value
许多方法都是基于key-value格式的RDD进行的,方法名中包含ByKey就意味着只能以pairRDD的类型进行操作。
通过keyBy函数,将普通rdd转换成kv形式

聚合操作
对普通RDD和kvRDD都可以进行聚合操作,有相应的groupByKey,reduceByKey。还有groupBy和reduceBy方法。
着重强调:不要使用groupByKey方法!!!!
这个方法需要在内存中保存一个key对应的所有value,然后进行计算。如果有严重的key倾斜现象,会出现OOM问题。
正确的聚合应该使用reduceByKey方法,reduce方法的计算发生在每个分组,将计算的中间结果进行传递汇总,不会导致OOM,也不会有shuffle的过程。


注意:因为是RDD,所以使用的addFunc是自己实现的。
控制分区
与结构化API不同,RDD允许指定一个分区函数partitioner,来精准控制数据在整个集群上的物理分布。
结构化的API不支持自定义分区。RDD支持,其目的是将数据均匀分布到整个集群,避免数据倾斜等问题。
一般使用过程是将DS或DF降级为RDD,应用自定义分区程序,再转回DF或DS
具体实现如下:



首先读取数据,转换为RDD,之后rdd转换为KeyedRDD,再调用partitionBy方法。需要传入一个partitioner类。此处自己实现了一个(继承Partitioner)。spark内置了两个partitioner,分别是处理离散值的HashPartitioner和处理连续值的RangePartitioner
自定义序列化
任何希望并行处理(或函数操作)的对象都必须是可序列话的。即需要继承Serializable
默认的序列化方式可能很慢。spark可以使用kryo库更快的进行序列化。
具体做法如下:
- 设置spark配置spark.serializer 的值为 org.apache.spark.serializer.KryoSerializer
- 注册自定义类

分布式共享变量
分布式共享变量包括两种
广播变量是共享的,不可修改的。缓存在集群中的每个节点上,而不是在每个任务中反复序列化。
具体使用如下:



首先创建一个map的val,之后通过sparkContext的broadcast方法创建一个广播变量suppBroadcast。之后就可以在RDD的相关操作,此处举例为map中使用了。具体使用方式是通过.value拿到对应的值。
累加器
累加器提供一个累加用的变量,Spark集群可以按行方式对其进行安全更新。仅支持由满足交换律和结合律的操作进行累加的变量。因此累加器可以高效并行。
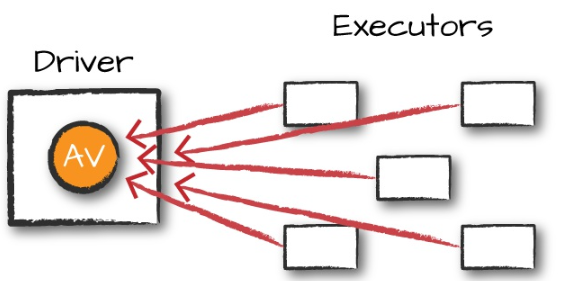
spark保证每个任务对累加器的更新只进行一次,重启的任务不会再更新。
具体使用如下:


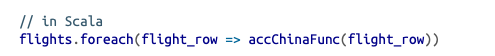
首先创建一个累加器,可以实例化后注册,也可以直接通过context创建。
之后定义一个累加方法,其中需要调用累加器的add方法进行累加操作
最后在DF上调用累加方法,实现累加功能foreach中每一行都运行一次累加方法。