Spark基础-生产与应用
Spark运行过程
程序架构
- driver:负责控制整个spark应用程序的执行并维护集群状态。与集群管理器交互以获得物理资源并启动executor
- executor:执行由driver分配的任务,上报结果
- 集群管理器:负责维护一组运行spark程序的机器。spark目前支持三种集群管理器:
- 内置独立管理器
- Mesos
- Hadoop YARN
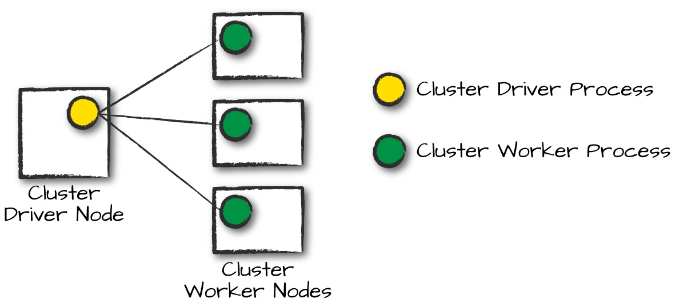
集群管理器由一个driver节点和若干工作节点构成,driver负责接收任务,并在worker节点启动任务。
执行模式
集群模式下,用户将预编译的Jar包提交给集群管理器,管理器在集群内某个工作节点启动driver进程。根据driver进程的请求,在集群工作节点上启动executor进程。
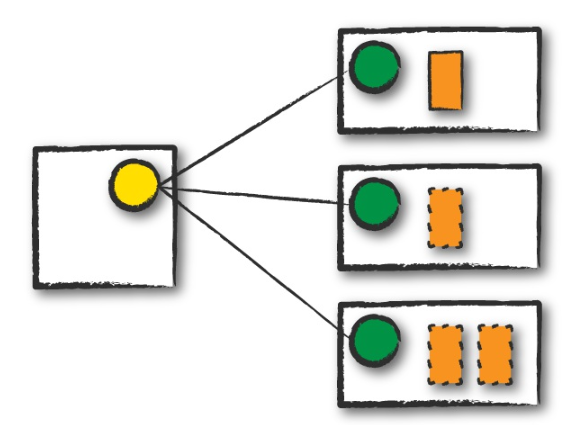
实线方框是spark的driver程序,虚线方框是spark的executor
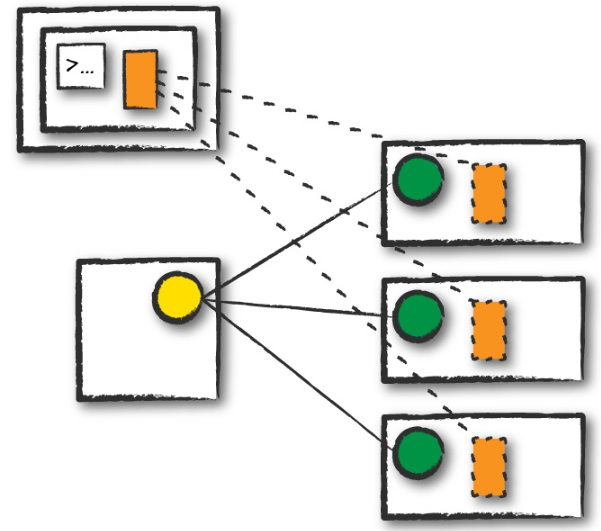
客户端模式
和集群模式几乎一样,不同点在于spark的dirver保存在提交应用的客户端机器上。这意味着客户端机器维护driver进程,集群管理器维护executor进程。
本地模式
调试使用,在一台机器上运行程序,通过线程实现并行。
Spark程序生命周期(外部)
客户请求
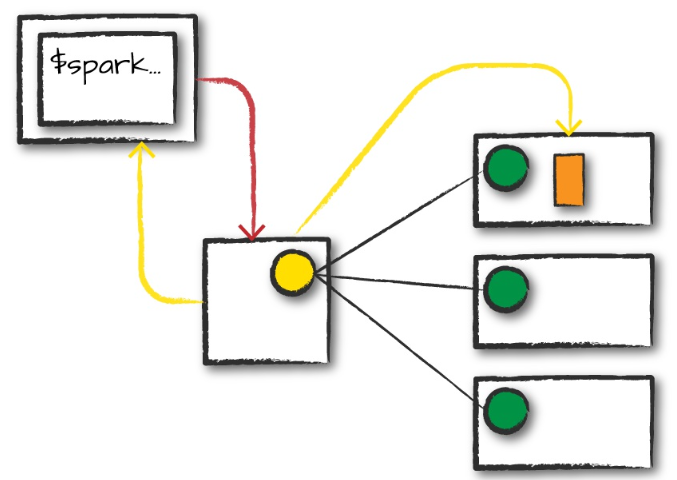
通过本地客户端请求集群管理器,提交jar包,发送启动命令(红线),这一步只为spark driver请求资源。
资源管理器接受请求,将spark driver 启动在一个worker上
之后客户端退出,程序开始在集群上运行。
命令类似:

启动
spark driver开始执行代码,代码必须包含初始化spark集群的sparkSession。ss之后和集群管理器diriver通信,要求启动spark executor。
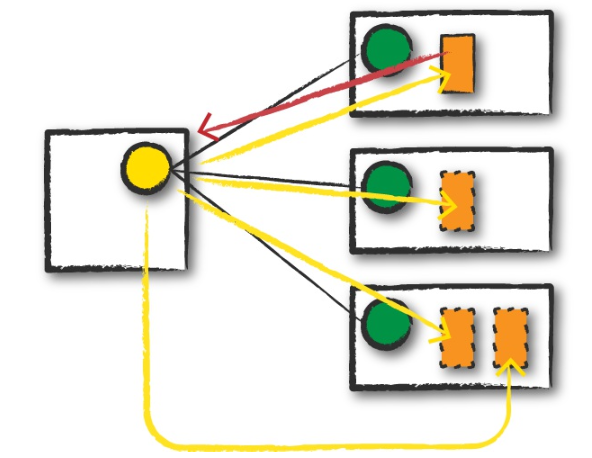
集群管理器会启动executor,并将executor位置等相关信息报告给spark driver
执行
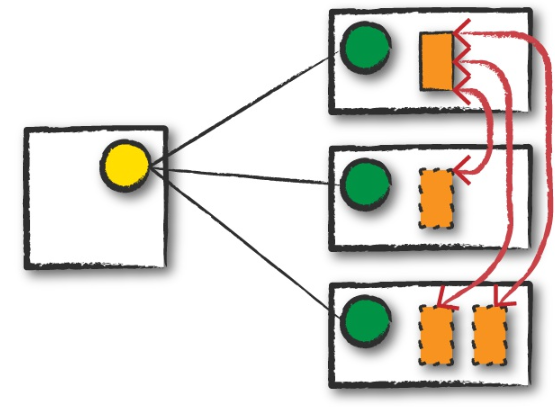
节点间相互通信,executor按照driver的指示执行任务,上报结果。executor之间进行数据交换。
完成
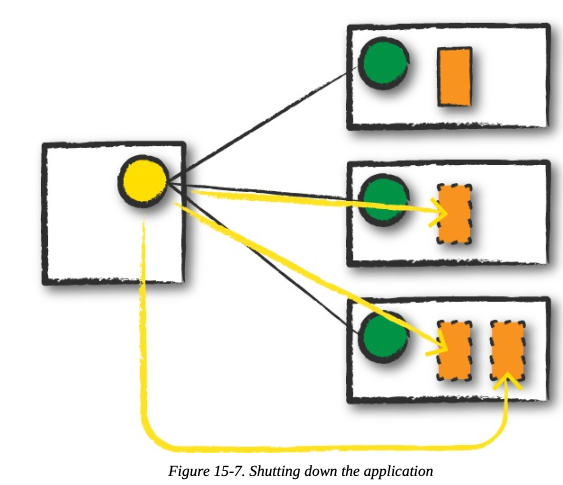
应用完成后,driver会以成功或失败的状态退出。之后集群管理器关闭所有executor。
Spark程序生命周期(内部)
sparkSession
第一步就是创建SparkSession,所有spark任务执行都基于此
逻辑指令
根据编写的程序生成逻辑指令,之后再转换成具体的物理执行计划。
Spark作业
一个动作应该触发一个spark作业,调用动作总是会返回结果。每个作业(Job)被分解成一系列阶段(stage),其数量取决于进行多少次的shuffle。
上面这句话非常重要,这是spark任务拆解的核心逻辑。这里的动作指的是spark中的动作操作。简单理解:
动作操作决定job数量,shuffle次数决定stage数量
作业
每个动作操作对应一个job,因此一个spark应用可以包含多个job,在spark UI中会有体现。
阶段
spark中stage代表可以一起执行的任务组,用于在多台机器上执行相同的操作。spark将尽可能多的操作加入同一个阶段。引擎在shuffle之后将启动新的阶段。一次shuffle是一次对数据的物理重分区。
任务
spark中的阶段由若干任务(task)构成,每个任务对应一组数据和一组将在单个executor上进行的转换操作。任务个数和数据分区个数相等。即每一个数据分区都有一个任务来处理。
执行细节
流水线执行
如果不需要跨节点的数据移动,spark将一系列操作合并为一个单独的任务阶段,直接在内存中完成。
shuffle数据持久化
如果需要跨节点,则进行shuffle操作,此时会将数据持久化到磁盘。在已经执行了shuffle操作的数据上运行新的作业时,不会重新运行生产shuffle数据的任务。因为这些任务的运行结果已经被保存在磁盘了,只需要读取进行后续操作即可。这也是UI和日志中有些阶段会被标记为SKIPPED的原因。
Spark UI
选项卡
spark UI界面包含如下选项卡

- jobs对应spark作业
- stages对应各个阶段和相关任务
- storage包含当前在spark应用程序中缓存的信息和数据
- environment对应spark应用相关配置信息
- SQL对应我们提交的结构化API查询(SQL和DF)
- executors对应每个执行器的详细信息
用下面的例子详细解读:


启动一个spark应用来执行上述代码,包含读取csv,重分区为2,做一次筛选,做一次分组,然后计算count,再将结果输出到driver。
根据is_glass分组,所以最终is_glass为true,为false,为null分别对应一个count值,输出三行数据。
对应的SQL UI如下:
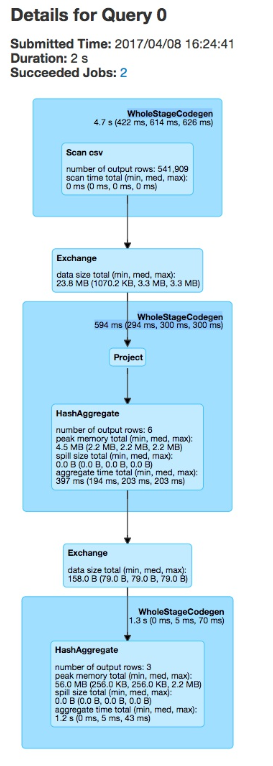
这里三个蓝色大框表示三个阶段,中间两个exchange小框就是进行了两次shuffle。可以看到,第一个阶段进行了csv文件的读取。然后执行repartiton,做了一次shuffle,将数据分为了2个分区。
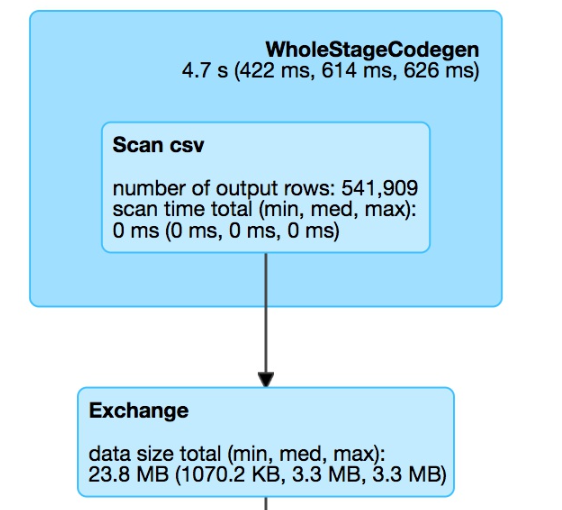
第二阶段进行数据处理,做过滤,做分组聚合。这里还没有进行下一次的shuffle即数据汇总。因此是在两个分区上分别进行的。按照分组计算count的逻辑,两个分组各产生3条数据,总共6条数据。
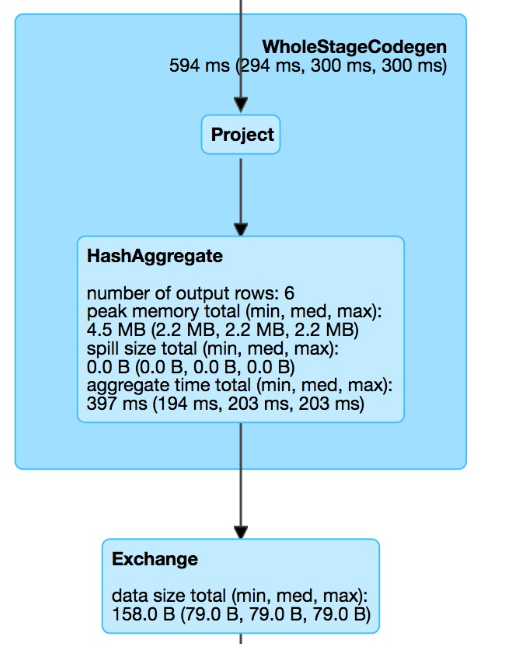
第三阶段将来自两个分区的最后三行执行结果合并,并作为总查询结果输出。

三个阶段的任务个数可以在UI中查看
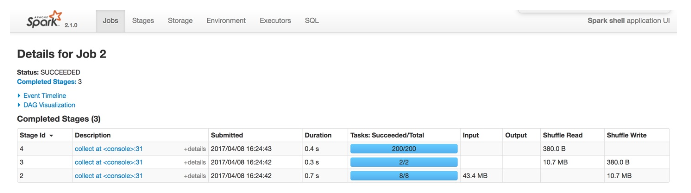
第一阶段有8个任务,第二阶段🈶2个,第三阶段有200个。
第一阶段的读取由8个任务并行执行,即将csv文件拆分成了8份进行。在集群上读取hdfs等可以拆分成更多份。
第二阶段有2个任务,因为我们人为指定了分区数为2
第三阶段有200个任务,因为默认的分区数是200,虽然如此,但真正能拿到数据的任务应该只有2个。
性能调优
性能调优遵循下面几个原则
API选择
尽量使用高级API,利用spark引擎的优化能力
序列化方式选择
开启kryo序列化
动态分配
根据工作负载动态调整应用占用的资源。spark.dynamicAllocation.enabled=true
数据存储
- 长期文件存储选择parquet格式
- 对表进行合理分区
- 分桶操作:分桶允许spark根据可能执行的连接操作或聚合操作对数据进行预先分区。可以提高稳定性和性能,避免数据倾斜。如果要根据某一列进行频繁的联结操作,则可以通过分桶来保证数据按照这一列进行了良好的分区
shuffle配置
shuffle中每个输出分区至少有几十兆字节的数据。保证每个工作节点不会太忙或太闲
shuffle操作代价高昂,但是如果通过平衡数据可以从整体上优化作业的执行,这个代价是值得的。一般shuffle尽可能少的数据。如果要减少分区数量,优先试试coalesce方法。
缓存
如果一个DF会被下游反复用到,可以选择显示指定将其缓存,这样下游无需重复执行生成DF的过程。
分区和分桶
分区(Partitioning):
- 分区是将数据集分割成较小的部分,每个分区可以在集群中的不同节点上进行处理。
- 分区可以通过对数据进行哈希分区、范围分区或列表分区来创建。
- 分区可以提高数据处理的并行性,同时减少数据传输的网络开销。
桶(Bucketing):
- 桶是将数据根据某个列的值进行分组,并将每个分组存储在独立的文件中。
- 桶可以根据数据的分布来优化查询性能,可以减少数据的扫描范围。
- 桶可以在创建表时指定,也可以在数据写入时进行动态分桶。