Akka基础-异常处理和容忍
actor的开启、停止和观测
通过context.actorof的方式来创建和启动一个actor,
停止actor有两种方法:
通过context.stop的方法来停止一个actor
通发送特定的毒药信息,所有接受到这条消息的actor都会停止(不推荐)
1 | |
- stop是异步方法,在真正执行停止命令之前还是会接收消息
- 还可以用context.stop(self)的方法来停止自己,会异步递归的停止所有子actor,再停止自身
- PoisonPill和kill两个特殊message用于停止接收到消息的actor
- context.watch(actor)方法用于监视某个actor的停止,当其停止时监视的actor能收到消息
actor的生命周期
概念解析:
- actor instance:拥有方法,可以拥有内部状态,就是一个实例
- actor reference:通过actorOf创建出来的引用,指向一个实例,同时mailbox和接收信息是属于ref的,有uuid
- actor path:path对应一个或0个ref
将这三者理解为一个嵌套引用的关系
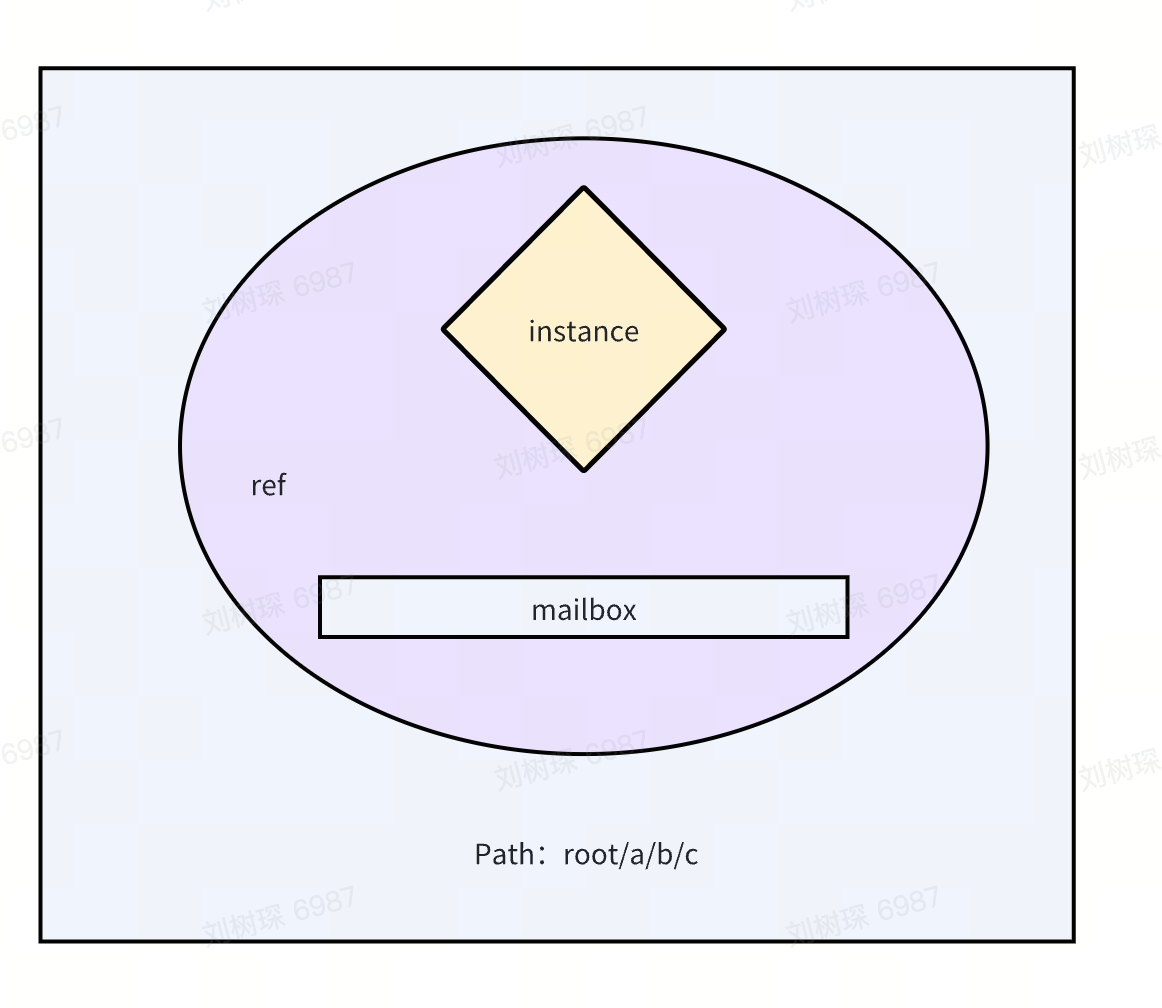
对于一个actor,它存在以下状态
- start:创建出了一个actor的实例和其引用,有uuid和path
- suspend:actor仍然存在,但不再处理消息
- resume:重新开始处理消息
- restart:是一个过程,内部维护的状态会失效,具体执行逻辑如下
- 先suspend
- 引用指向的旧实例执行preRestart方法
- 构建一个新的实例,引用指向新实例
- 新实例执行postRestart方法
- stop:彻底销毁,停止
actor可以崩溃,父actor需要决定当其子actor崩溃后的处理方式,同时需要在自己崩溃时对上下游负责
当actor失败时需要:
停止其所有子actor
向其父actor发送特殊的消息
当父actor接收到子actor的失败消息时可以选择如下操作:暂停这个actor
重启这个actor(默认)
停止这个actor
上升这个失败,自己也向上报失败
在实现中,通过重写SupervisorStrategy来指定遇到不同的异常时进行不同的操作,这个策略会被自动应用在其子actor失败的时候
OneForOneStrategy() 方法可以传入两个参数 maxNrOfRetries和withinTimeRange,分别表示最大重试次数和多久之内执行完
1 | |
看下面这个测试,首先创建supervisor actor,通过传入Props的形式创建出它的子actor。然后向它的子actor发送消息,引发异常,supervisor会按照策略对子actor进行处理
1 | |
总结:
akka基于失败重启的策略,实现了对于执行异常的容忍和自愈机制,使得整个系统更加的稳定健壮,这就是所谓的让其崩溃的思路。
Akka基础-异常处理和容忍
http://www.bake-data.com/2024/07/15/Akka基础-异常处理和容忍/